
14 Monte Carlo Methods
When you hear the words “Monte Carlo”, most people envision this:

…or this:

But when I hear Monte Carlo, I envision this:

No, that’s not some grainy image coming into focus - that’s a Monte Carlo simulation approximating the value of \(\pi\) (3.1415927…).
14.1 What is Monte Carlo simulation?
14.1.1 Basic idea
Monte Carlo simulation uses (pseudo)random numbers to solve (not-so-random) problems. The general approach goes like this:
- Run a series of trials.
- In each trial, simulate an event (e.g. a coin toss, a dice roll, etc.).
- Count the number of successful trials.
- Guess that the Expected Odds \(\simeq\) Observed Odds = \(\frac{\text{\# Successful Trials}}{\text{\# Total Trials}}\)
For many applications, Monte Carlo simulations result in a sufficiently accurate result with a reasonable amount of trials (~ 100,000). You can always improve your accuracy with more trials, but that comes at the expense of increased run time. To summarize:
- As # of trials increases, observed odds –> expected odds.
- More trials –> more accurate (+ more time).
14.1.2 Why the name “Monte Carlo”?
The name “Monte Carlo” comes from the (pseudo)random nature of the simulation process. Running a series of trials is similar to how many gambling games work in casinos, and Monte Carlo is famous for gambling. Of course, in the casinos the odds are always slightly in the favor of the house, so after millions of trials the odds are that the house will win more money than the gamblers.
14.1.3 Why even do this?
Many problems have “closed-form” solutions, meaning they can be solved with math alone. But there are also many problems for which no known closed-form solution exists. Integration is a classic example - there are many integrals for which a purely mathematical solution cannot be determined. However, solutions can be approximated using simulation.
R comes with many tools for running (pseudo)random simulations, which is one reason R is such a popular programming language for people who build and work with statistical models that involve simulations.
14.2 Monte Carlo integration
Integration is ultimately about computing the area below the curve of a function. Let’s take a simple example - suppose we want to find the integral from 3 to 7 of the following function:
\[f(x) = x^2\]
That is, we want to compute the area under the curve of \(x^2\) between \(3 < x < 7\). Here’s what that looks like:
One way to estimate the shaded area is to draw a bunch of random points inside a rectangle in the x-y plane that contains the shaded area and then count how many fall below the function line. So we’re going to randomly draw points inside this box:
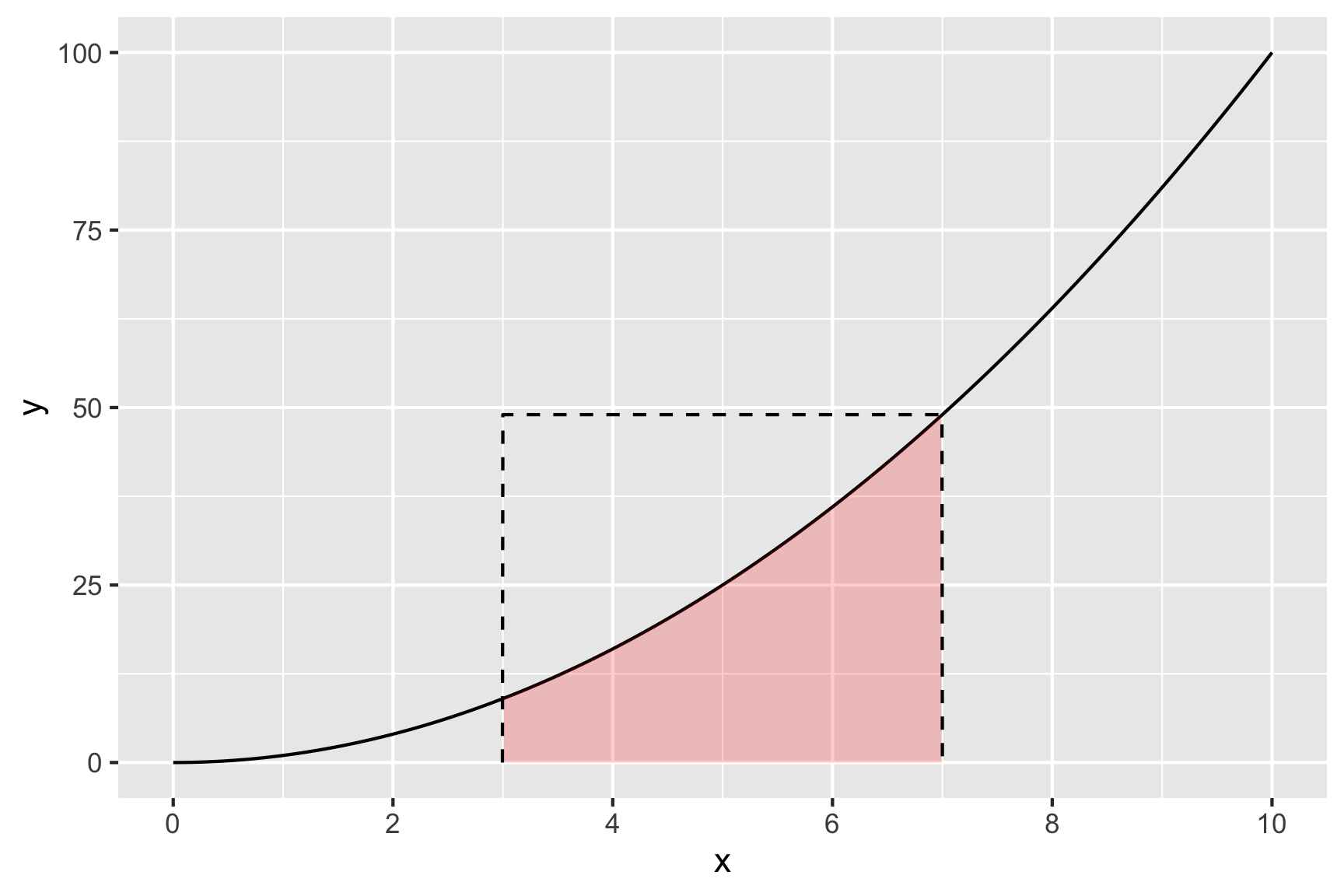
Let’s simulate some random points inside the box:
numTrials <- 100000
# The function runif() samples from a "uniform" distribution
x <- runif(numTrials, min = 3, max = 7) # Values of x between 3 and 7
y <- runif(numTrials, min = 0, max = 7^2) # Values of y between 0 and 7^2Now that we have our points, we can use them to estimate the area under the curve. The logic here is that the ratio of points below the curve to the total number of points will be equal to the ratio of the area under \(f(x)\) to the total area of the rectangle. That is:
\[\frac{\text{\# Points Under Curve}}{\text{\# Total Points}} = \frac{\text{Area Under Curve}}{\text{Area of Rectangle}}\]
So, to get the area under the curve, we need to compute the area of the rectangle and multiply it by \((\text{\# Points Under Curve}) / (\text{\# Total Points})\). We know the total area of the rectangle is its length (\((7 - 3) = 4\)) times its height (\(7^2\)), which is \(4 * 49 = 196\). So the area under the curve should be 196 times the ratio of points under the curve to the total number of points. Let’s write the code!
# Determine which y points are less than or equal to x^2:
belowCurve <- y <= x^2 # Creates a vector of TRUE and FALSE values
# Compute the ratio of points below the curve:
ratio <- sum(belowCurve) / numTrials
totalArea <- (7 - 3) * 7^2 # length x height
areaUnderCurve <- ratio * totalArea
areaUnderCurve#> [1] 105.2363So, using Monte Carlo simulation with 100,000 points, we estimate that the area under the curve is 105.23632. How’d we do? Well, if you’re familiar with calculus, the integral of \(f(x) = x^2\) has a closed-form solution (\(\frac{x^3}{3} + C\)), so we can check our estimate against the pure-math solution:
\[ \int_{3}^{7} x^2 \mathrm{dx} = \left ( \frac{x^3}{3} \right ) \Big|_3^7 = \frac{7^3}{3} - \frac{3^3}{3} = 105.33\bar{3} \]
So our estimate error is: 105.333 - 105.23632 = 0.0970133.
That’s an error of just 0.09 % - not bad!
14.3 Monte Carlo \(\pi\)
Now let’s look at something a bit trickier - approximating \(\pi\)!
Watch this quick video to see a summary of how this works (…I hope you like lounge music)
Now let’s approximate \(\pi\) ourselves! Let’s start with some basic geometry.
The area of a circle is:
\(A_{circle} = \pi r^2\)
If we draw a square containing that circle, its area will be:
\(A_{square} = 4r^2\)
This is because each side of the square is simply \(2r\), as can be seen in this image:

Knowing these two equations for the areas of a circle and square, we can compute \(\pi\) by taking the ratio, \(R\), of the area of a circle to that of a square containing that circle:
\(R = \dfrac{\pi r^2}{4r^2} = \dfrac{\pi}{4}\)
So to compute \(\pi\), all we need to do is multiply 4 times the ratio of the area of the circle to that of the square. Just like with integration, we can approximate that ratio by simulating lots of points in the square and then simply counting the number that fall inside the circle.
Let’s write the code!
First, generate lots of random points in a square. For this example, we’ll use a square with side length of 1 centered at (x, y) = (0, 0), so we need to draw random points between x = (-0.5, 0.5) and y = (-0.5, 0.5):
numTrials <- 10000
points <- data.frame(
x = runif(numTrials, -0.5, 0.5),
y = runif(numTrials, -0.5, 0.5)
)
head(points)#> x y
#> 1 0.229506132 -0.08053840
#> 2 -0.007594905 0.04727206
#> 3 0.109975740 0.18632628
#> 4 -0.219826613 0.35889460
#> 5 -0.011846287 -0.09219395
#> 6 -0.175026551 -0.23989452For this example, we’re putting the points in a data frame to make it easier to work with. Now that we have random x and y points, let’s compute the radius to each point (the distance from (x, y) = (0, 0)) so we can determine which points fall inside the circle (which has a radius of 0.5):
library(dplyr)
points <- points %>%
mutate(
radius = sqrt(x^2 + y^2),
pointInCircle = radius <= 0.5
)Just to make sure we correctly labeled the points, let’s plot them, coloring them based on the pointInCircle variable we just created:
library(ggplot2)
ggplot(points) +
geom_point(
aes(x = x, y = y, color = pointInCircle),
size = 0.5
) +
theme_minimal()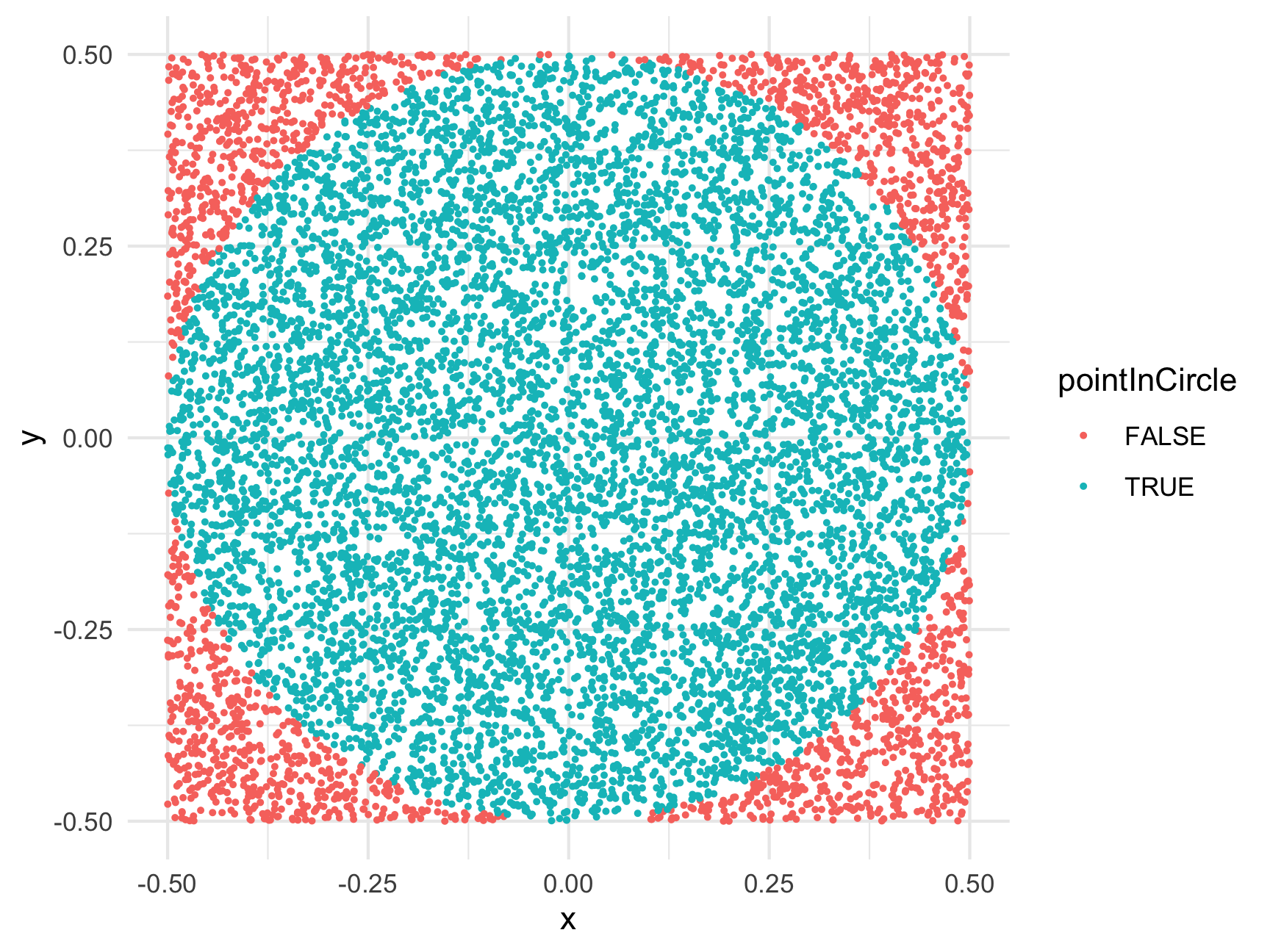
Looks like we correctly labeled the points! Now we have everything we need to estimate \(\pi\)!
ratio <- sum(points$pointInCircle) / nrow(points)
piApprox <- 4 * ratio
piApprox#> [1] 3.1256So our estimate error is: 3.1415 - 3.1256 = -0.0159927.
That’s an error of just 0.51 % - not bad for only 1,000 points!
To get an even better estimate of \(\pi\), we can increase N. Let’s see what we get with 100,000 trials:
numTrials <- 100000
points <- data.frame(
x = runif(numTrials, -0.5, 0.5),
y = runif(numTrials, -0.5, 0.5)) %>%
mutate(
radius = sqrt(x^2 + y^2),
pointInCircle = radius <= 0.5
)
ratio <- sum(points$pointInCircle) / nrow(points)
piApprox <- 4 * ratio
piApprox#> [1] 3.13876# Compute error:
error <- piApprox - pi
percentError <- round(100*abs(error / pi), 2)
percentError#> [1] 0.09By increasing the number of trials from 1,000 to 100,000, we improved our estimate error from 0.51 % to 0.09 %!
Page sources
Some content on this page has been modified from other courses, including: